
- Le problème : pourquoi Spark standard est lent
- Architecture : Velox + Apache Gluten
- Row-based vs Columnar : le cœur du gain
- Benchmarks : les chiffres concrets
- Hands-on : benchmark sur 76M lignes de NYC Taxi
- Comment activer le Native Execution Engine
- Le mécanisme de fallback
- Limitations actuelles
- Bonnes pratiques et recommandations
Ce n'est pas qu'un article théorique. La section 5 présente un benchmark exécuté dans un vrai workspace Fabric sur 76.5 millions de lignes — avec les résultats bruts et l'analyse du cold start.
Si vous exécutez des jobs Apache Spark dans Microsoft Fabric, vous avez probablement déjà remarqué que certaines requêtes prennent du temps — parfois beaucoup plus que ce que les volumes de données justifient. La raison ? Le moteur Spark standard repose sur la JVM et un traitement ligne par ligne qui n'exploite pas pleinement le matériel moderne.
Le Native Execution Engine change la donne. C'est une couche d'accélération en C++ qui s'intègre de manière transparente à Spark, sans modifier votre code, et qui peut multiplier les performances par 4 à 6. Dans cet article, on va décortiquer son architecture, comprendre pourquoi il est si rapide, et voir comment l'activer dans vos workspaces.
Le Native Execution Engine est GA (Generally Available) sur le Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2). Il est prêt pour la production. Le support sur Runtime 1.2 est désactivé — migrez vers 1.3 si ce n'est pas déjà fait.
01. Le problème : pourquoi Spark standard est lent
Pour comprendre le Native Execution Engine, il faut d'abord comprendre ce qui limite le Spark classique. Le moteur standard de Spark exécute les opérations ligne par ligne dans la JVM (Java Virtual Machine). Chaque ligne est traitée individuellement, ce qui génère plusieurs goulets d'étranglement :
- Overhead JVM — allocation mémoire, garbage collection, sérialisation/désérialisation à chaque opération
- Mauvaise localité mémoire — les valeurs d'une même colonne sont dispersées en mémoire, ce qui tue les performances du cache CPU
- Pas de vectorisation — le CPU traite une valeur à la fois au lieu d'utiliser les instructions SIMD modernes
- Warm-up JVM — le JIT compiler a besoin de temps pour optimiser le bytecode, ce qui pénalise les requêtes courtes
Résultat : sur des workloads lourds (aggregations, jointures, transformations complexes), une grande partie du temps CPU est consommée par l'overhead du runtime plutôt que par le traitement effectif des données.
02. Architecture : Velox + Apache Gluten
Le Native Execution Engine repose sur deux projets open source majeurs qui remplacent la couche d'exécution JVM par du code natif C++ optimisé.
Velox (Meta)
- Bibliothèque d'accélération C++ créée par Meta
- Moteur vectorisé en colonnes
- Kernels optimisés pour aggregations, jointures, filtres
- Zero garbage collection
- Exploitation native du SIMD
Apache Gluten (Intel)
- Couche intermédiaire (bridge) entre Spark et Velox
- Convertit les plans Spark en plans natifs
- Gère le fallback vers la JVM si nécessaire
- Projet Apache en incubation
- Transparent pour le code utilisateur
Comment ça s'intègre à Spark
Le point clé : Spark continue de faire ce qu'il fait de mieux — l'interface utilisateur, la planification, la distribution, la tolérance aux pannes. C'est uniquement la couche d'exécution physique qui est remplacée par du code natif.
Flux d'exécution
Les étapes en vert sont exécutées nativement en C++ — les autres restent dans l'écosystème Spark standard
Concrètement, après l'optimisation par Catalyst (predicate pushdown, column pruning, adaptive query execution...), Gluten intercepte le plan physique, identifie les opérateurs supportés nativement, et les remplace par des nœuds Velox. Les opérateurs non supportés restent sur la JVM avec des conversions colonnes ↔ lignes automatiques.
03. Row-based vs Columnar : le cœur du gain
C'est ici que la magie opère. La différence fondamentale entre le Spark standard et le Native Execution Engine tient à la façon dont les données sont organisées en mémoire.
Traitement Row-based (Spark standard)
Dans le modèle classique, les valeurs d'une même ligne sont stockées ensemble en mémoire. Pour calculer la somme d'une colonne montant, le CPU doit "sauter" d'une ligne à l'autre, traversant à chaque fois des colonnes inutiles. Résultat : cache misses en pagaille et zero possibilité de vectorisation.
Traitement Columnar (Native Execution Engine)
Avec le traitement en colonnes, toutes les valeurs d'une même colonne sont stockées de manière contiguë en mémoire. Cela permet :
- Localité mémoire optimale — le cache CPU est pleinement exploité, les données sont lues séquentiellement
- Vectorisation SIMD — une seule instruction CPU traite 8, 16, voire 32 valeurs simultanément
- Zero overhead JVM — pas de garbage collection, pas de sérialisation, pas de warm-up
- Compatibilité native Parquet/Delta — ces formats sont déjà en colonnes, donc zero conversion nécessaire
Imaginez une bibliothèque. Le mode row-based, c'est comme si chaque étagère contenait un livre de chaque genre. Pour trouver tous les romans, vous devez parcourir chaque étagère. Le mode columnar, c'est une étagère entière dédiée aux romans — vous les trouvez tous d'un coup.
04. Benchmarks : les chiffres concrets
Les chiffres parlent d'eux-mêmes. Microsoft a publié des benchmarks basés sur le standard industriel TPC-DS (1 To, format Delta).
| Benchmark | Spark Standard | Native Engine | Gain |
|---|---|---|---|
| TPC-DS 1 TB (Delta) | Baseline | Jusqu'à 6x plus rapide | ~83% de réduction |
| NYC Taxi (76.5M lignes) | 210.87s (4 queries) | 118.46s global / 10.8x à chaud | Testé en pratique |
Sur un cluster Fabric à capacité fixe, un gain de 6x en performance équivaut à environ 83% de réduction des coûts compute. Ce n'est pas un coût additionnel — c'est le même cluster, le même code, juste un moteur d'exécution plus intelligent.
Où les gains sont maximaux
- Aggregations complexes (GROUP BY, ROLLUP, CUBE) — bénéficient pleinement de la vectorisation
- Jointures larges (Hash Joins, Broadcast Joins) — traitement en batch natif
- Filtres et projections — predicate evaluation vectorisée
- Transformations de colonnes — opérations mathématiques et string parallélisées
Où les gains sont moindres
- Workloads I/O-bound — si le goulot est le réseau ou le stockage, l'accélération compute aide moins
- Requêtes simples — sur des scans basiques, l'overhead de conversion peut annuler le gain
- UDFs Python/Scala — non supportées nativement, elles forcent un fallback JVM
05. Hands-on : benchmark sur 76M lignes de NYC Taxi
Les chiffres Microsoft sont impressionnants, mais rien ne vaut un test sur un vrai workspace Fabric. J'ai exécuté un benchmark complet sur le dataset NYC Taxi (76 513 115 lignes, 23 colonnes, format Delta/Parquet) dans un notebook Fabric.
Workspace : Dojo DEV (Fabric Trial Capacity) • Lakehouse : DataFactoryLakehouse • Runtime : 1.3 (Spark 3.5) • Dataset : NYC Taxi — 76.5M lignes, format Delta
Les 4 requêtes du benchmark
Quatre requêtes de complexité croissante, chacune poussant un aspect différent du moteur :
# Q1 - GROUP BY simple : revenu moyen par compagnie
df.groupBy("vendorID").agg(
avg("totalAmount"), count("*"), sum("tipAmount")
)
# Q2 - GROUP BY multi-colonnes + métriques
df.groupBy("vendorID", "passengerCount").agg(
avg("totalAmount"), avg("tripDistance"),
sum("tipAmount"), count("*")
)
# Q3 - Filtre + aggregation + tri
df.filter(col("tripDistance") > 5) \
.groupBy("vendorID").agg(
avg("totalAmount"), avg("tripDistance"),
sum("fareAmount"), stddev("tipAmount")
).orderBy(desc("avg(totalAmount)"))
# Q4 - Paires de localisation + heavy aggregation
df.groupBy("puLocationId", "doLocationId").agg(
count("*"), avg("totalAmount"),
avg("tripDistance"), sum("tipAmount"),
avg("fareAmount")
).orderBy(desc("count(1)"))Résultats : SANS Native Execution Engine
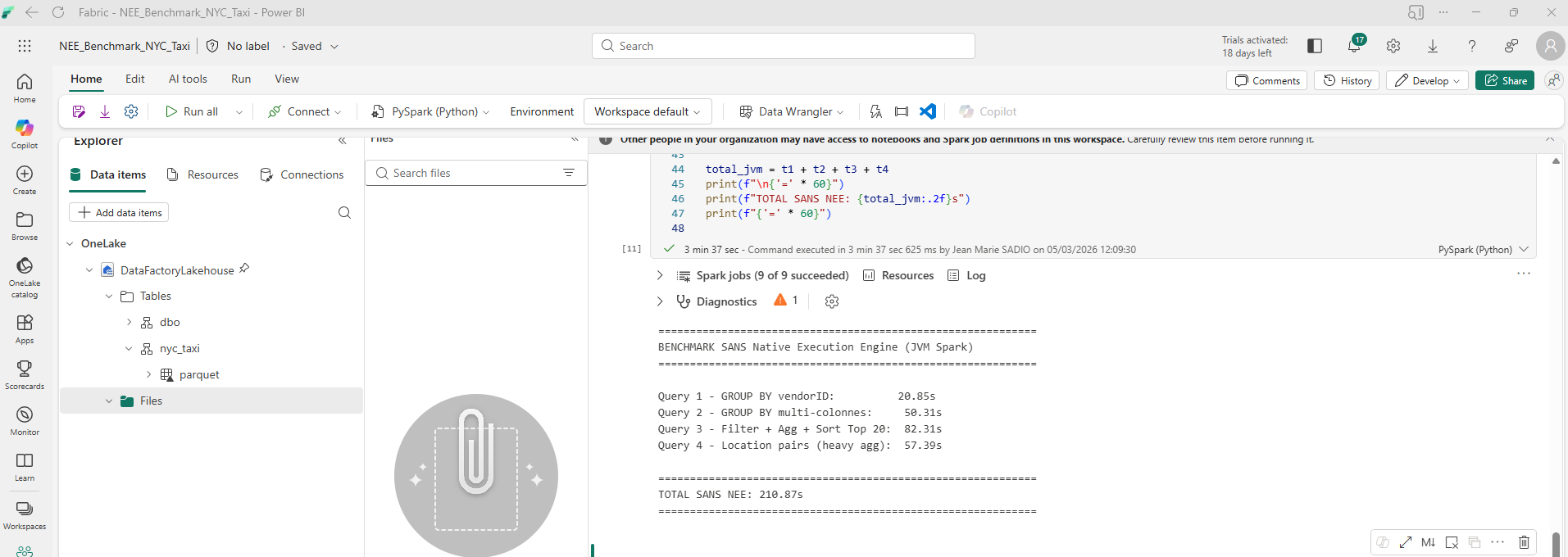
| Requête | Description | Temps (s) |
|---|---|---|
| Q1 | GROUP BY simple | 20.85s |
| Q2 | GROUP BY multi-colonnes | 50.31s |
| Q3 | Filtre + aggregation + tri | 82.31s |
| Q4 | Paires de localisation | 57.39s |
| TOTAL | 210.87s | |
Résultats : AVEC Native Execution Engine
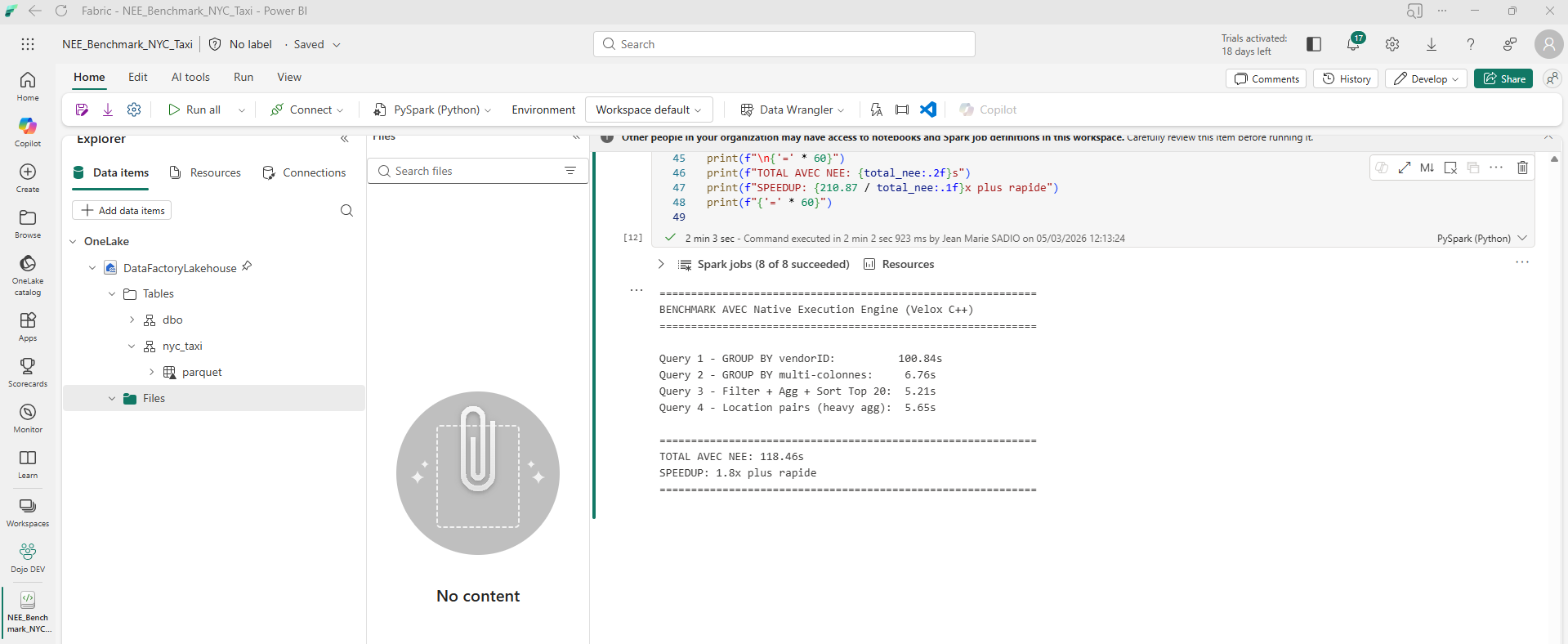
| Requête | Sans NEE | Avec NEE | Speedup |
|---|---|---|---|
| Q1 — GROUP BY simple | 20.85s | 100.84s * | 0.2x (cold start) |
| Q2 — GROUP BY multi | 50.31s | 6.76s | 7.4x |
| Q3 — Filtre + agg + tri | 82.31s | 5.21s | 15.8x |
| Q4 — Heavy aggregation | 57.39s | 5.65s | 10.2x |
| TOTAL | 210.87s | 118.46s | 1.8x global |
| Q2+Q3+Q4 (à chaud) | 190.01s | 17.62s | 10.8x |
Analyse des résultats
La première requête avec NEE (Q1 = 100.84s) est plus lente que sans NEE (20.85s). C'est normal : le moteur Velox doit se charger en mémoire, initialiser ses structures de données et compiler les kernels natifs. Ce coût est amorti sur les requêtes suivantes.
Les résultats sont éloquents. Une fois le moteur Velox initialisé, les performances explosent :
- Q2 (GROUP BY multi-colonnes) passe de 50.31s à 6.76s — 7.4x plus rapide
- Q3 (Filtre + aggregation + tri) passe de 82.31s à 5.21s — 15.8x plus rapide
- Q4 (Heavy aggregation) passe de 57.39s à 5.65s — 10.2x plus rapide
Sur les queries à chaud (Q2-Q4), le speedup moyen atteint 10.8x — bien au-delà des chiffres officiels Microsoft. La requête Q3 (filtre + aggregation complexe + tri) bénéficie le plus de la vectorisation : c'est exactement le type de workload où le traitement en colonnes et le SIMD font toute la différence.
Le cold start pénalise la première requête, mais les queries suivantes sont spectaculairement plus rapides. En production, où les sessions Spark tournent en continu, ce cold start est amorti dès les premières minutes. Le speedup réel en conditions normales est bien supérieur au 1.8x global observé ici.
06. Comment activer le Native Execution Engine
Trois niveaux d'activation possibles, du plus large au plus précis.
Niveau 1 : Activation par Environment
C'est la méthode recommandée pour activer le moteur sur tous les jobs et notebooks d'un environnement.
- Ouvrez votre Environment dans le workspace
- Allez dans Spark compute → Acceleration
- Cochez "Enable native execution engine"
- Cliquez sur Save and Publish
Activez-le au niveau Environment pour bénéficier de l'accélération sur tous vos notebooks et jobs sans avoir à modifier chaque fichier. L'intégration avec les Live Pools fait que le changement prend effet immédiatement, sans redémarrer de session.
Niveau 2 : Activation par Notebook / Spark Job Definition
Pour activer le moteur sur un seul notebook, ajoutez cette cellule de configuration en première position :
%%configure
{
"conf": {
"spark.native.enabled": "true"
}
}Niveau 3 : Contrôle par cellule
Vous pouvez activer ou désactiver le moteur pour une cellule spécifique. Utile si une requête utilise une feature non supportée.
# Désactiver le NEE pour cette cellule (ex: UDF non supportée)
spark.conf.set('spark.native.enabled', 'false')
# ... votre code avec UDF ici ...
# Réactiver pour les cellules suivantes
spark.conf.set('spark.native.enabled', 'true')07. Le mécanisme de fallback
C'est l'un des aspects les plus intelligents du Native Execution Engine : quand un opérateur n'est pas supporté nativement, il revient automatiquement sur la JVM Spark standard. Aucune erreur, aucune interruption.
Comment ça fonctionne
- Gluten analyse le plan d'exécution physique
- Les opérateurs supportés sont remplacés par des nœuds Velox
- Les opérateurs non supportés restent sur la JVM
- Des conversions colonnes ↔ lignes automatiques assurent la transition
Chaque fallback implique une conversion colonnes → lignes (et inversement), ce qui a un coût. Si votre job contient beaucoup de fallbacks, le gain global peut être réduit voire annulé. Utilisez le Spark Advisor pour identifier et corriger ces cas.
Comment identifier les fallbacks
Trois méthodes pour vérifier quels opérateurs s'exécutent nativement :
- Spark UI — dans le graphe d'exécution, les nœuds natifs sont en vert et portent le suffixe
TransformerouNativeFileScan - df.explain() — le plan physique affiche les nœuds natifs avec le suffixe
Transformer - Onglet Gluten SQL / DataFrame — tableau de bord dédié montrant le ratio nœuds natifs vs JVM par requête
08. Limitations actuelles
Le Native Execution Engine est puissant, mais il a encore des limitations à connaître avant de l'activer en production.
Limitations principales
| Limitation | Détail | Workaround |
|---|---|---|
| UDFs | Les User Defined Functions ne sont pas accélérées | Utiliser les fonctions built-in Spark quand possible |
| Formats JSON/CSV/XML | Non accélérés par le moteur natif | Convertir en Parquet ou Delta avant traitement |
| Structured Streaming | Non supporté | Utiliser le traitement batch |
| Mode ANSI SQL | Incompatible, provoque un fallback complet | Désactiver le mode ANSI |
array_contains() |
Fonction non supportée nativement | Reformuler avec EXISTS ou FILTER |
| Runtime 1.2 | Support supprimé | Migrer vers Runtime 1.3 |
Subtilités à connaître
- Cast DECIMAL → FLOAT — Velox effectue un cast direct qui peut produire des arrondis différents de Spark JVM
- Timezones non reconnues — un format comme
"-08:00"peut faire échouer le job sous NEE alors que la JVM le tolère round()— comportement d'arrondi légèrement différent dû à l'implémentationstd::rounden C++collect_list()avec SORT BY — l'ordre des éléments peut varier par rapport à Spark standard
Si votre workspace utilise des managed private endpoints vers un storage account, vous devez configurer des endpoints séparés pour Blob (blob.core.windows.net) et DFS (dfs.core.windows.net), même s'ils pointent vers le même compte. Un seul endpoint ne suffit pas avec le NEE.
09. Bonnes pratiques et recommandations
Voici mes recommandations pour tirer le maximum du Native Execution Engine en production.
Activez-le par défaut
Le NEE est GA, stable, et ne coûte rien de plus. Activez-le au niveau Environment et désactivez-le ponctuellement par cellule si nécessaire. Le fallback automatique garantit que vos jobs ne casseront pas.
Privilégiez Parquet et Delta
Le moteur est optimisé pour ces formats en colonnes. Si vous ingérez du CSV ou du JSON, ajoutez une étape de conversion en Delta dans votre pipeline avant les transformations lourdes. Vous bénéficierez de l'accélération sur toute la suite du traitement.
Remplacez vos UDFs par des built-ins
Les UDFs sont la première cause de fallback. Vérifiez si une fonction native Spark peut remplacer votre UDF. Dans la majorité des cas, une combinaison de when(), regexp_extract(), ou transform() fait le même travail — en beaucoup plus rapide.
Monitorez les fallbacks
Utilisez l'onglet Gluten SQL / DataFrame du Spark UI pour identifier les requêtes avec un ratio élevé de nœuds JVM. Ce sont vos cibles d'optimisation prioritaires.
Testez les cas limites
Avant de déployer en production, validez le comportement de round(), des casts DECIMAL, et des timezones sur vos données réelles. Les différences sont subtiles mais peuvent impacter vos résultats.
# Comparer les résultats avec et sans NEE
spark.conf.set('spark.native.enabled', 'true')
df_native = spark.sql("SELECT round(2.5), cast(123.456 as float)")
spark.conf.set('spark.native.enabled', 'false')
df_jvm = spark.sql("SELECT round(2.5), cast(123.456 as float)")
# Vérifier que les résultats sont identiques
df_native.exceptAll(df_jvm).show()∑ Récapitulatif
| Aspect | Détail |
|---|---|
| Technologie | Velox (Meta) + Apache Gluten (Intel), moteur vectorisé C++ |
| Performance | Jusqu'à 6x (TPC-DS), 10.8x observé sur NYC Taxi 76M lignes |
| Coût supplémentaire | Aucun — même cluster, même capacité |
| Modification de code | Aucune — activation par configuration |
| Runtime requis | Runtime 1.3 (Spark 3.5, Delta Lake 3.2) |
| Formats optimaux | Parquet et Delta |
| Principales limitations | UDFs, JSON/CSV/XML, Structured Streaming |
| Sécurité | Fallback automatique vers la JVM si opérateur non supporté |
Le Native Execution Engine est probablement la feature la plus impactante de Fabric Data Engineering en 2025-2026. Un gain de performance significatif, zero effort de migration, zero coût supplémentaire. Si vous ne l'avez pas encore activé, c'est le moment de le faire.
Des questions ou des retours d'experience ? Retrouvez-moi sur LinkedIn.
Sources & Références
- Under the hood: an introduction to the Native Execution Engine - Microsoft Fabric Blog
- Native Execution Engine for Fabric Data Engineering - Microsoft Learn
- Native Execution Engine now Generally Available - Microsoft Fabric Blog
- Velox - C++ Database Acceleration Library (Meta) - GitHub
- Apache Gluten (incubating) - GitHub