
- Le problème : ingestion manuelle depuis SharePoint
- Architecture de la solution
- Étape 1 — Lakehouse et OneLake Shortcut
- Étape 2 — Configuration metadata-driven
- Étape 3 — Notebook PySpark d'ingestion
- Étape 4 — Pipeline Fabric
- Étape 5 — Logic App Azure (automatisation)
- Test end-to-end et résultats
- Troubleshooting : les pièges rencontrés
- Analyse des coûts
Dans beaucoup d'organisations, les équipes métier déposent des fichiers critiques (CSV, Excel) sur SharePoint : rapports de ventes, données clients, exports financiers. Mais importer manuellement ces fichiers dans un Lakehouse à chaque nouveau dépôt, c'est chronophage, risqué et ne passe pas à l'échelle.
Et si chaque fichier déposé dans un dossier SharePoint était automatiquement ingéré dans une Delta table dans Microsoft Fabric — sans aucune intervention humaine ?
Dans cet article, je vous montre une solution production-ready que j'ai construite et testée : fichier SharePoint → Logic App → Pipeline Fabric → Delta table. De bout en bout, entièrement automatisé.
01. Le problème : ingestion manuelle depuis SharePoint
Voici le scénario typique que vivent la plupart des équipes data :
- Les utilisateurs métier uploadent des fichiers CSV/Excel sur SharePoint régulièrement
- Un data engineer doit manuellement télécharger, transformer et charger les données
- Si le fichier change, le processus recommence de zéro
- Aucun audit trail, aucune automatisation, aucune scalabilité
Ce workflow manuel crée des goulots d'étranglement et des retards dans la disponibilité des données. Nous avons besoin d'un pipeline event-driven qui réagit instantanément quand un fichier arrive sur SharePoint.
02. Architecture de la solution
SharePoint (fichiers CSV/XLSX)
|
v
Azure Logic App (trigger : fichier créé/modifié)
|
v HTTP POST --> Fabric Pipeline API
|
LoadSharePoint_Pipeline
|
+-- LoadSharepoint.ipynb (notebook principal)
| +-- Lecture fichier via OneLake shortcut
| +-- Application config metadata (Fabric.csv)
| +-- Sanitization des noms de colonnes
| +-- Écriture Delta table (merge ou overwrite)
|
+-- Notification email (succes/echec)La beaute de cette architecture tient dans sa simplicite : 4 composants, entièrement managés, coût quasi-nul.
| Composant | Rôle | Coût |
|---|---|---|
| OneLake Shortcut | Lien direct vers SharePoint (zéro copie) | Gratuit |
| Fabric Notebook | Lecture + transformation + écriture Delta | Inclus dans la capacité |
| Fabric Pipeline | Orchestration + passage de parametres | Inclus dans la capacité |
| Logic App (Consumption) | Détection fichier + déclenchement pipeline | ~0.01€/mois |
03. Étape 1 — Lakehouse et OneLake Shortcut
La première étape consiste à créer un Lakehouse dans Fabric capable de voir directement les fichiers SharePoint, sans aucun job de copie ou de synchronisation.
1Créer le Lakehouse
Dans votre workspace Fabric, créez un nouveau Lakehouse nomme LH_SharePoint.
2Créer le shortcut OneLake
- Naviguez vers Files > clic droit > New shortcut
- Sélectionnez SharePoint comme source
- Entrez l'URL de votre site SharePoint
- Parcourez la bibliothèque de documents et sélectionnez le dossier cible (ex :
FabricTest) - Nommez le shortcut
FabricTest
Création du shortcut OneLake pointant vers le dossier FabricTest sur SharePoint
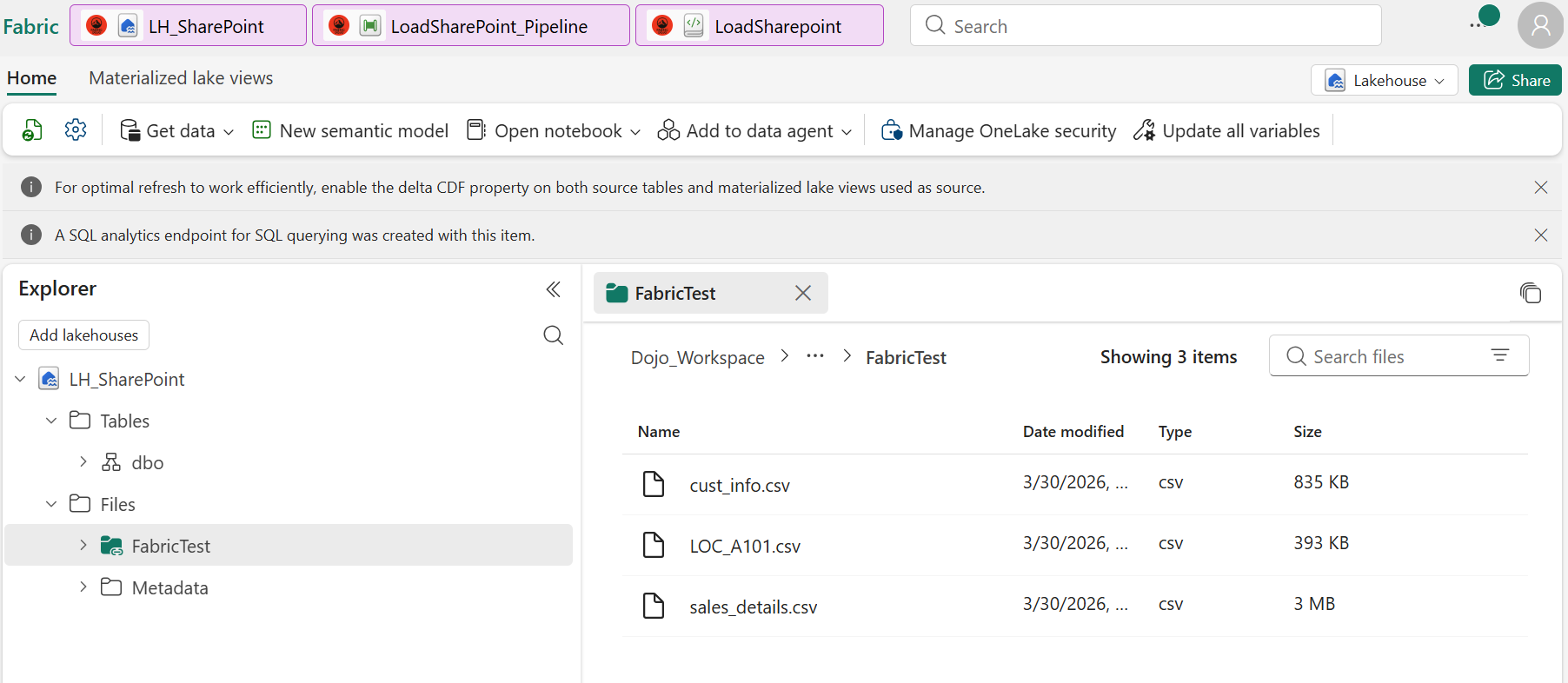
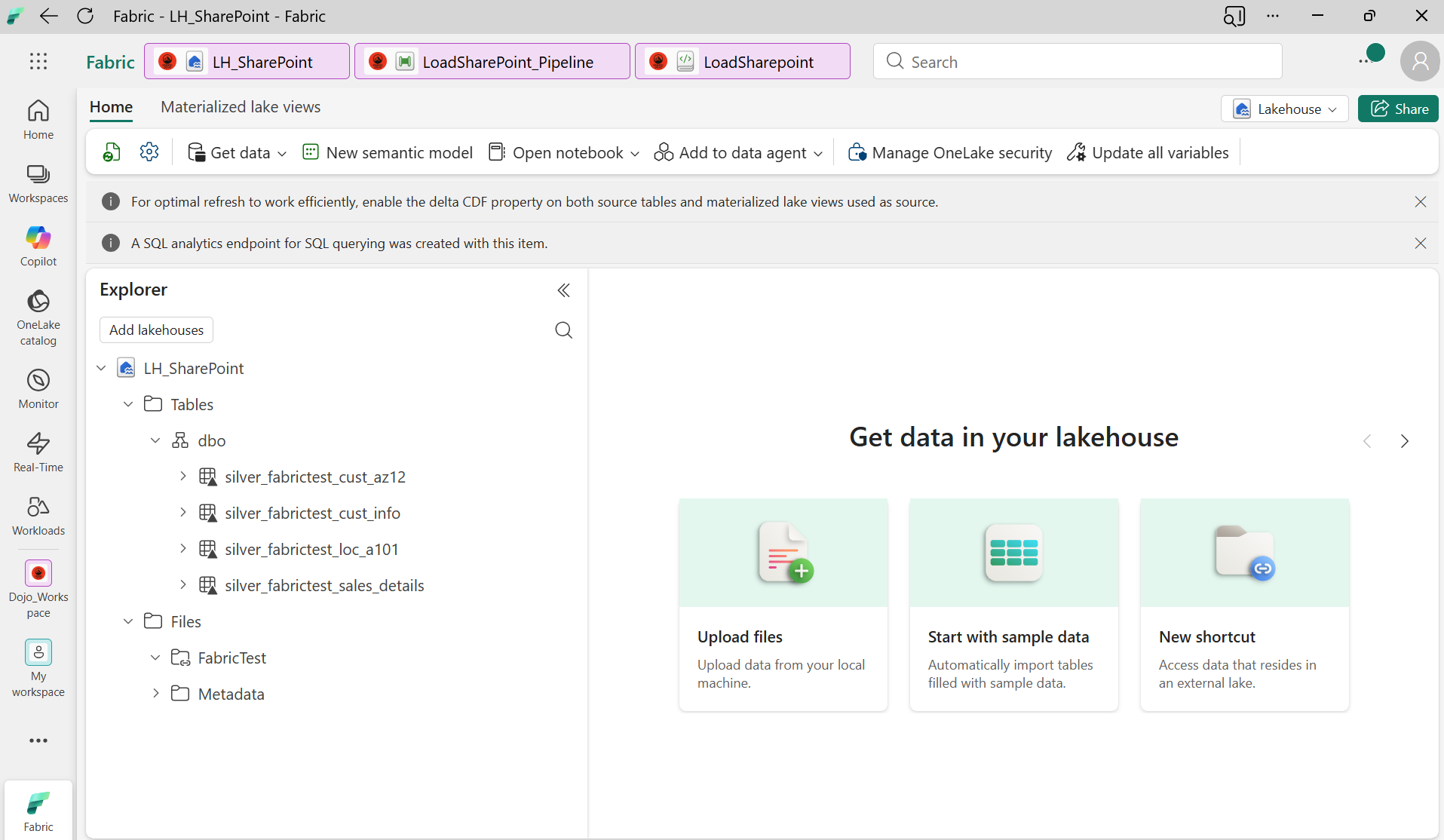
Une fois créé, les fichiers SharePoint sont visibles directement dans le Lakehouse sous Files/FabricTest/ — aucune duplication de données, aucun ETL, juste un lien en direct.
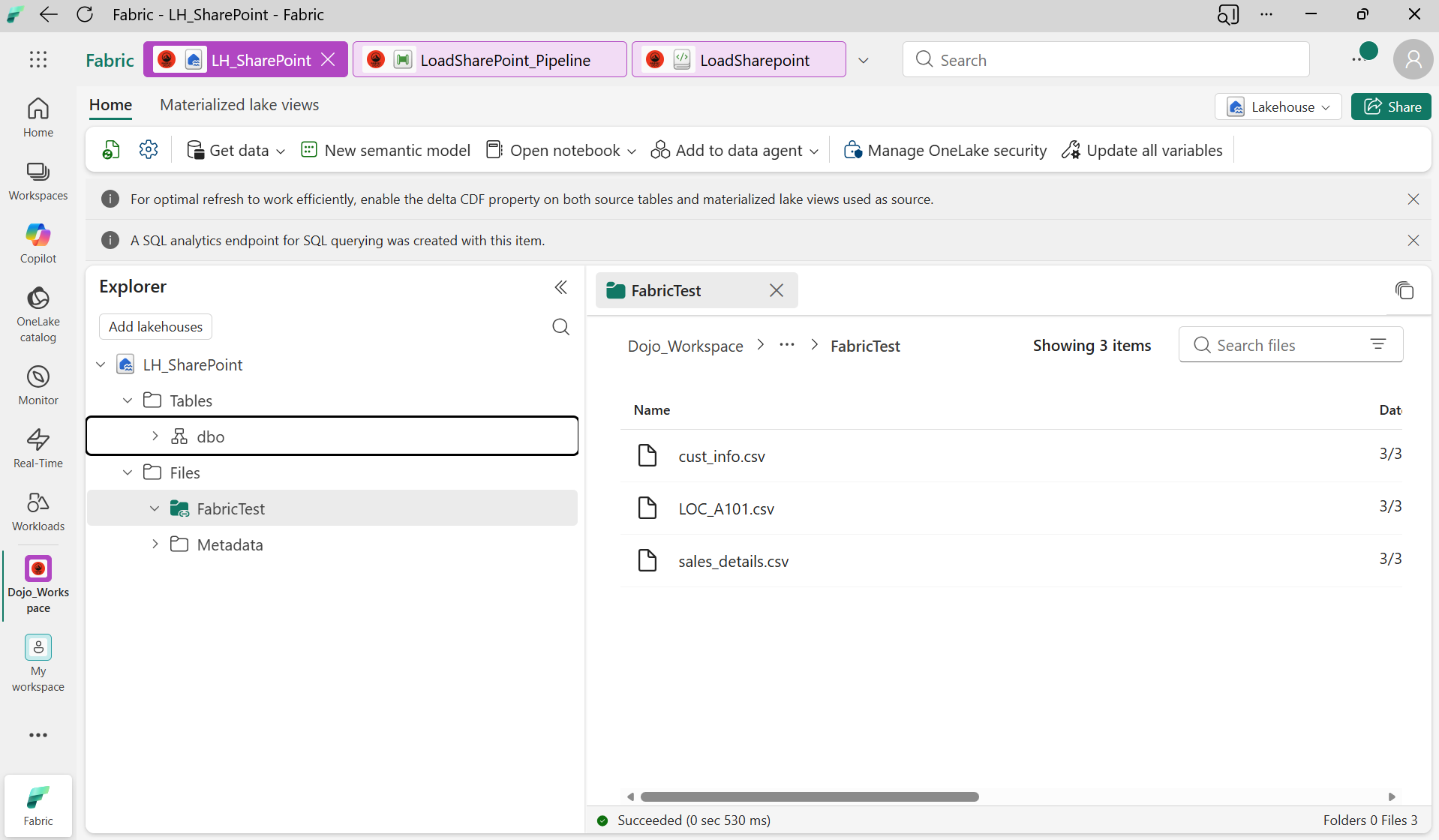
Les fichiers CSV SharePoint sont accessibles directement depuis le Lakehouse
Le shortcut cree une vue en direct des fichiers SharePoint dans OneLake. Les fichiers ne sont pas copiés — ils sont lus à la demande. Cela signifie zéro coût de stockage côté Fabric.
04. Étape 2 — Configuration metadata-driven
Le fichier de métadata Fabric.csv contrôle comment chaque fichier est traité. Uploadez-le dans Files/Metadata/ de votre Lakehouse.
| Colonne | Description | Exemple |
|---|---|---|
FullFolderPath |
Shortcut + nom fichier (sans extension) | FabricTest/orders |
LoadType |
full (overwrite) ou delta (merge) |
full |
UniqueKey |
Colonnes pour le merge delta | OrderId,OrderDate |
Header |
Numéro de ligne du header (0 = première) | 0 |
SkipRow |
Nombre de lignes à sauter | 0 |
SilverTableName |
Nom custom de la table (sinon auto) | silver_orders |
Cette approche metadata-driven signifie que vous pouvez intégrer de nouveaux fichiers sans changer une seule ligne de code — il suffit d'ajouter une ligne au CSV.
05. Étape 3 — Notebook PySpark d'ingestion
Le notebook LoadSharepoint est le cœur de la solution. Il gère à la fois les fichiers CSV et Excel, avec sanitization automatique des colonnes et support du merge Delta.
Décisions de conception
- Résolution dynamique du chemin : le notebook reçoit juste le nom du fichier et construit le chemin complet via le shortcut
- Traitement métadata-driven : type de chargement, clés de merge et noms de tables sont tous configurables
- Sanitization des colonnes : les caractères spéciaux sont supprimés pour assurer la compatibilité Delta
- Évolution de schéma : quand une table existe déjà, le notebook cast les colonnes source pour matcher le schéma cible
Configuration et extraction du chemin
# Configuration du shortcut
SHORTCUT_NAME = "FabricTest"
# Paramètre du pipeline (injecté par Fabric Pipeline)
FullPath = "sales_details.csv" # Valeur par défaut pour tests manuels
# Extraction des details du fichier
parts = FullPath.strip("/").split("/")
FileName = parts[-1].split(".")[0]
FileExt = parts[-1].split(".")[-1]
# Construction du chemin via le shortcut
file_path = f"Files/{SHORTCUT_NAME}/{parts[-1]}"La valeur FullPath = "sales_details.csv" dans le notebook est juste une valeur par défaut pour les tests manuels. Quand le pipeline est déclenché par la Logic App, cette valeur est automatiquement remplacée par le vrai nom du fichier.
Logique de merge Delta
def mergeTableData(metadatadf, source_df, tbl_name=None):
source_df = sanitizeColumnsName(source_df)
if (spark.catalog.tableExists(tbl_name)
and metadatadf.select("LoadType").first()[0] == "delta"):
# Delta merge sur les cles uniques
target_table = DeltaTable.forName(spark, tbl_name)
target_table.alias("target") \
.merge(source_df.alias("source"), merge_condition) \
.whenMatchedUpdateAll() \
.whenNotMatchedInsertAll() \
.execute()
else:
# Full overwrite
source_df.write.format("delta") \
.mode("overwrite") \
.saveAsTable(tbl_name)Traitement CSV et Excel
if FullPath.lower().endswith('.csv'):
source_df = spark.read.option("header", True).csv(file_path)
mergeTableData(metadatadf, source_df)
elif FullPath.lower().endswith('.xlsx'):
all_sheets = pd.read_excel(
excel_file_path,
sheet_name=None,
engine='openpyxl',
)
# Chaque feuille devient sa propre table Delta
for sheet_name, pdf in all_sheets.items():
source_df = spark.createDataFrame(pdf)
mergeTableData(metadatadf, source_df, sheet_table)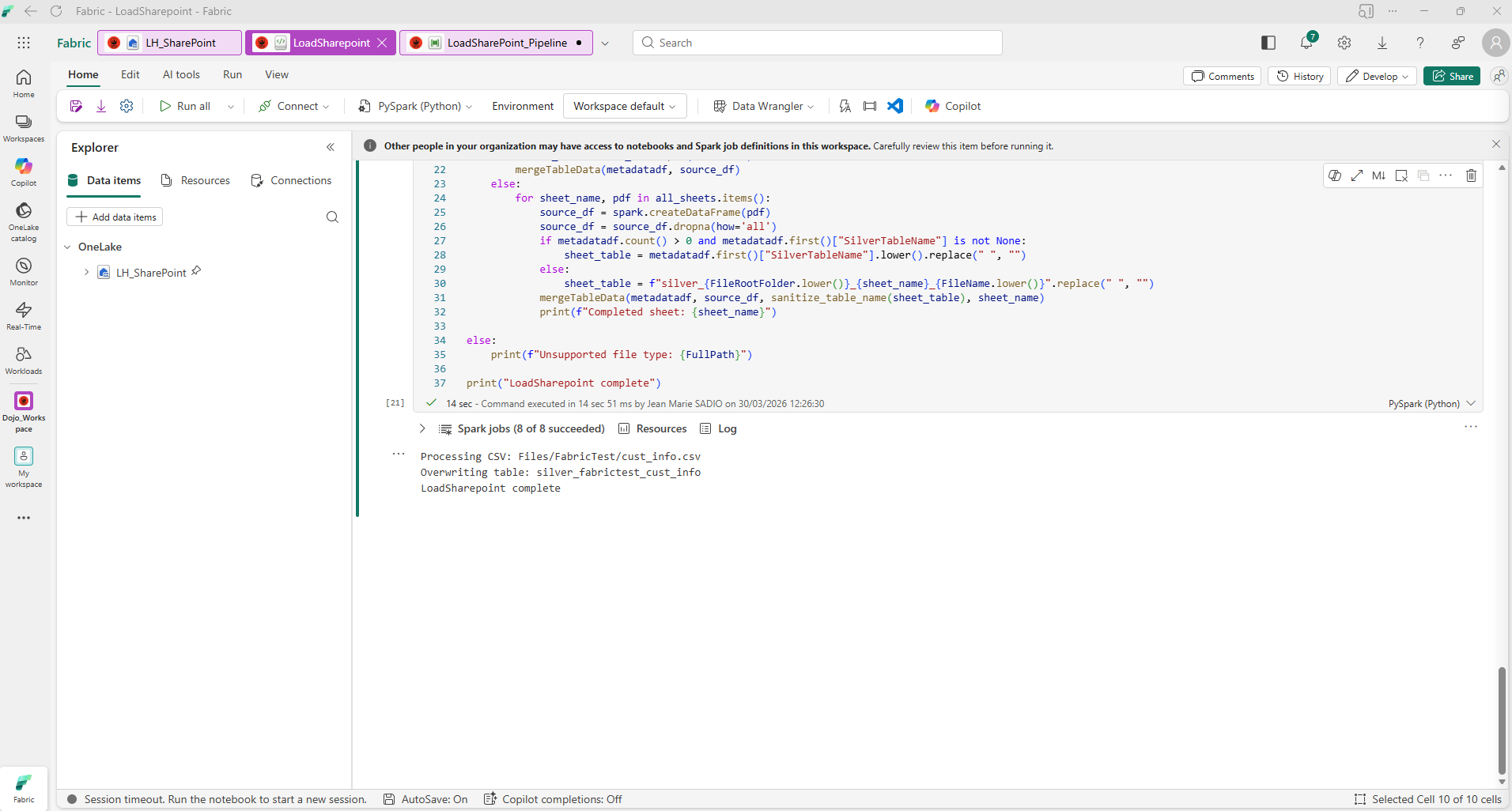
Le notebook traite le fichier CSV et crée la Delta table automatiquement
Convention de nommage : les tables sont auto-nommées silver_{shortcut}_{filename}. Par exemple :
cust_info.csv→silver_fabrictest_cust_infosales_details.csv→silver_fabrictest_sales_detailsLOC_A101.csv→silver_fabrictest_loc_a101
06. Étape 4 — Pipeline Fabric
Le pipeline orchestre l'exécution du notebook et gère les notifications succès/échec.
- Créez un nouveau Data Pipeline nomme
LoadSharePoint_Pipeline - Ajoutez un paramètre :
FullPath(type String) - Ajoutez une activité Notebook (
Run_LoadSharepoint) :- Notebook :
LoadSharepoint - Base parameter :
FullPath=@pipeline().parameters.FullPath - Lakehouse :
LH_SharePoint
- Notebook :
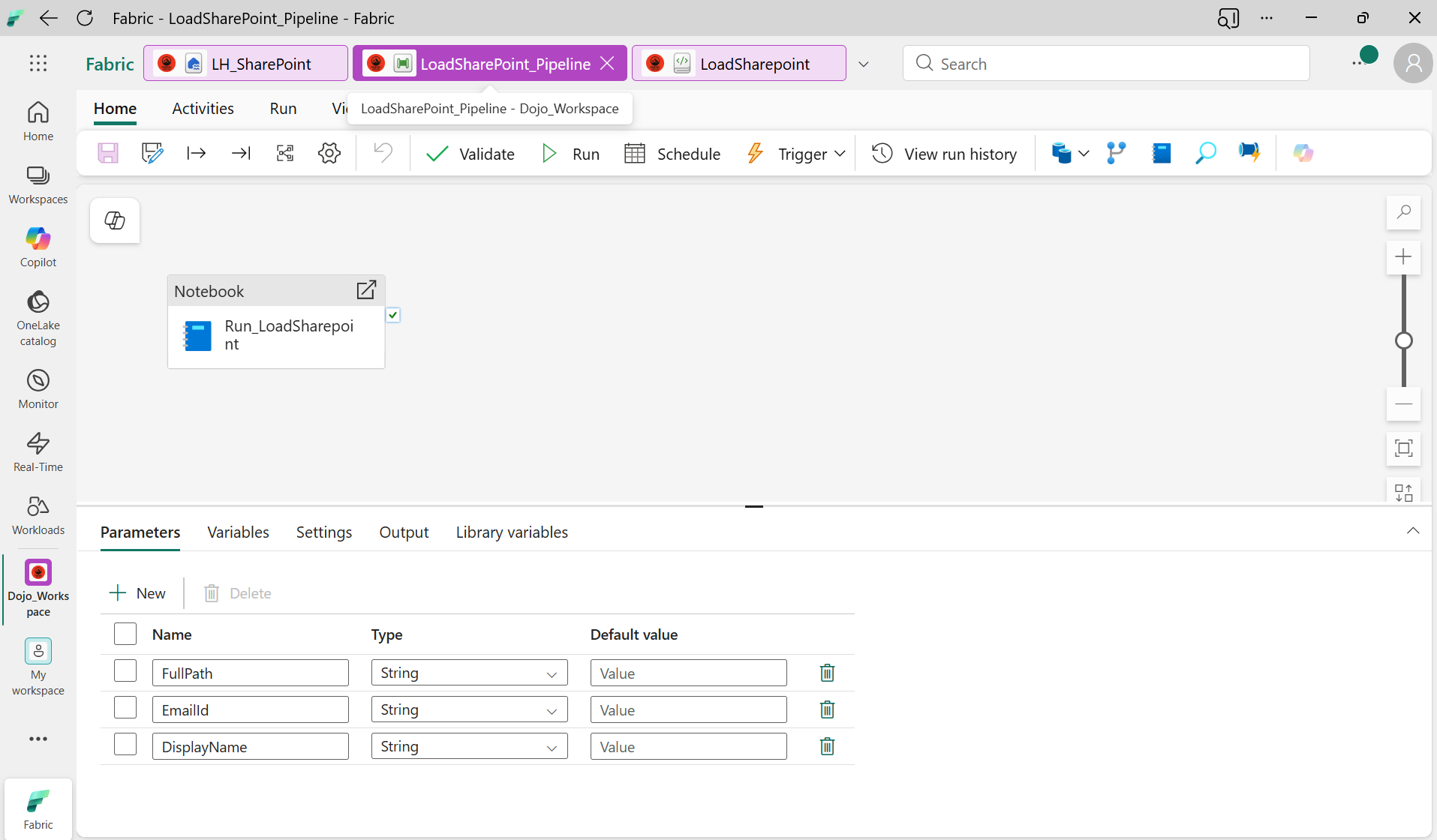
Pipeline avec l'activité Notebook et le mapping du paramètre FullPath
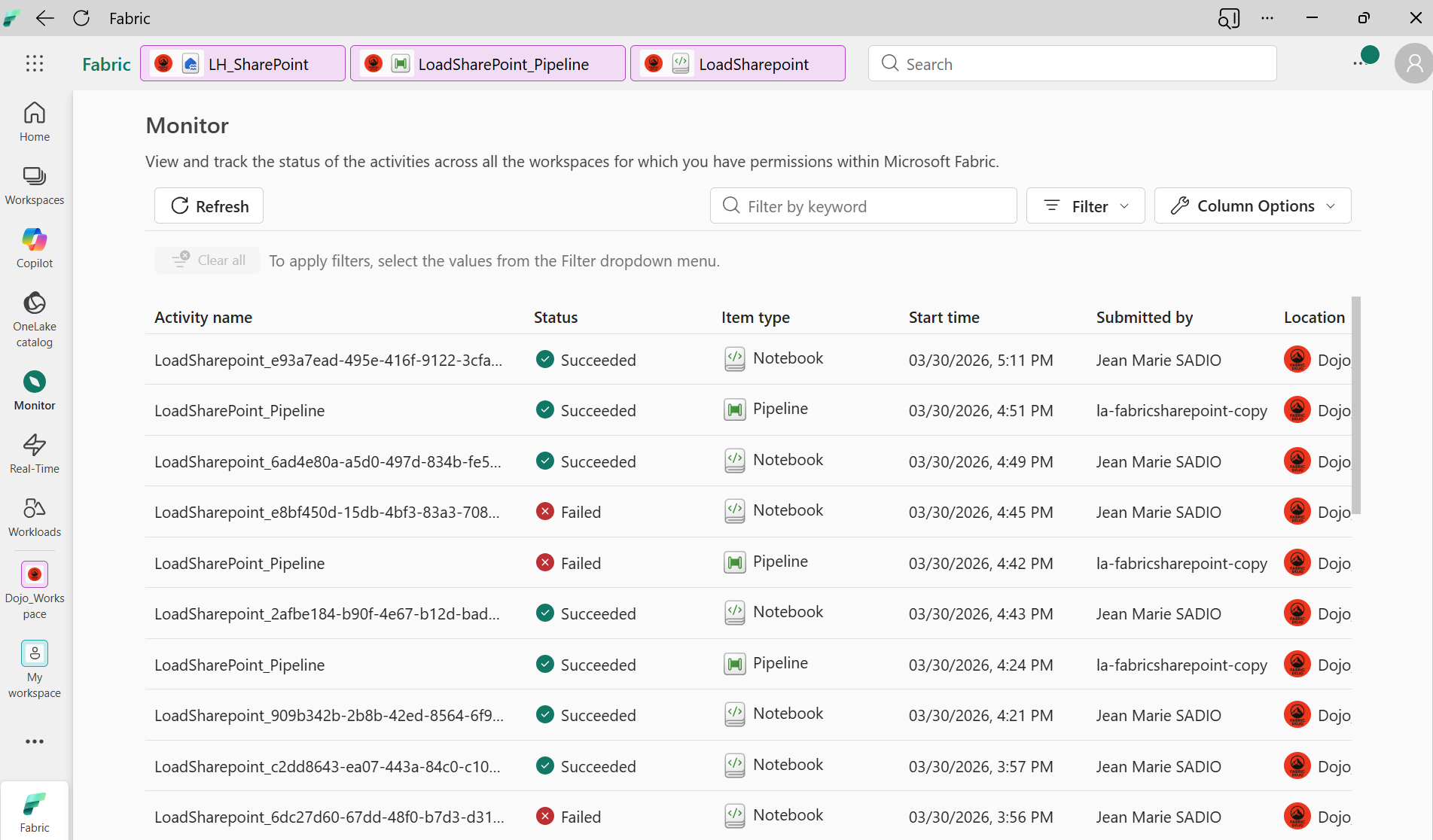
Premier test manuel : pipeline exécuté avec succès, Delta table créée
07. Étape 5 — Logic App Azure (automatisation)
C'est ici que la magie opère — la Logic App surveille SharePoint et déclenche le pipeline automatiquement.
ACréer la Logic App
- Dans le portail Azure, créez une Logic App (Consumption)
- Nommez-la
la-fabricsharepoint-copy - Region : même que votre workspace Fabric (ex : France Central)

Création de la Logic App en mode Consumption (pay-per-execution)
Choisissez Consumption (pas Standard). Le plan Consumption facture ~0,000025€ par action — vous ne paierez quasiment rien pour cette charge. Le plan Standard coûte beaucoup plus cher et n'est pas nécessaire ici.
BActiver le Managed Identity
- Allez dans Settings > Identity
- Activez le System assigned managed identity
- Copiez l'Object ID

Managed Identity system-assigned activee — pas de mots de passe, pas de clés API
CAccorder les permissions dans Fabric
- Dans Fabric, allez dans votre workspace > Manage access
- Cliquez Add people or groups
- Cherchez
la-fabricsharepoint-copy - Assignez le role Contributor
DConfigurer le workflow
Trigger SharePoint :
| Paramètre | Valeur |
|---|---|
| Site Address | URL de votre site SharePoint |
| Library Name | Votre bibliothèque de documents |
| Folder | /Shared Documents/FabricTest |
| Interval | 3 minutes |
Action HTTP — POST vers l'API Fabric :
| Paramètre | Valeur |
|---|---|
| Method | POST |
| URI | https://api.fabric.microsoft.com/v1/workspaces/{id}/items/{id}/jobs/instances?jobType=Pipeline |
| Headers | Content-Type: application/json |
| Authentication | Managed Identity |
| Audience | https://api.fabric.microsoft.com |
{
"executionData": {
"parameters": {
"FullPath": "@{triggerOutputs()?['body/{FilenameWithExtension}']}"
}
}
}
Workflow complet : trigger SharePoint → HTTP POST vers l'API Fabric
L'audience d'authentification doit etre https://api.fabric.microsoft.com — PAS https://analysis.windows.net/powerbi/api. L'audience Power BI ne fonctionne pas pour l'API REST Fabric. C'est un bug subtil qui fait échouer le pipeline en moins d'1 seconde, sans message d'erreur explicite.
08. Test end-to-end et résultats
Le moment de vérité : déposons un nouveau fichier CSV dans le dossier SharePoint FabricTest et observons le flux complet.
- Upload d'un fichier
LOC_A101.csvdans SharePoint - ~3 minutes plus tard, la Logic App détecte le fichier
- La Logic App envoie un HTTP POST a l'API Fabric avec
FullPath = LOC_A101.csv - Le pipeline démarre et le notebook s'exécute
- La table
silver_fabrictest_loc_a101est créée automatiquement

Logic App : trigger SharePoint (0.3s) + HTTP action (1m 2s) — les deux en succès

L'API Fabric retourne 200 avec le statut "InProgress" — le pipeline est lancé
Résultat final : 3 Delta tables créées automatiquement — zéro intervention manuelle
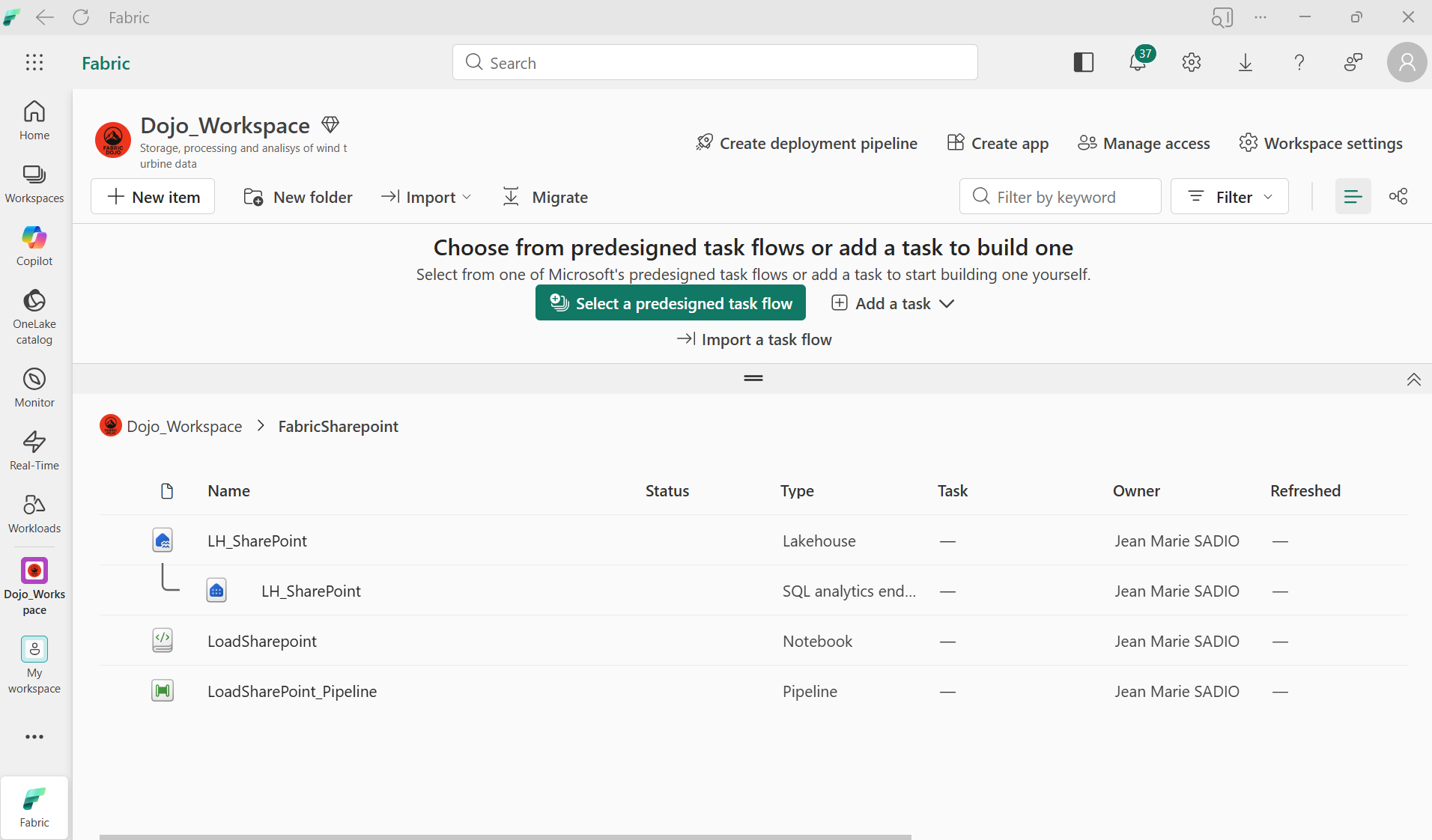
Vue globale du workspace Fabric — Lakehouse, SQL endpoint, Notebook et Pipeline
Résultat final
silver_fabrictest_cust_info— données clients (835 KB)silver_fabrictest_sales_details— détails de ventes (3 MB)silver_fabrictest_loc_a101— données localisation (393 KB) — créée automatiquement par la Logic App
09. Troubleshooting : les pièges rencontrés
Pendant la construction de cette solution, j'ai rencontré plusieurs problèmes. Voici ce que j'ai appris :
Piège 1 : Pipeline échoue en moins d'1 seconde
Symptome : La Logic App retourne 200, mais le pipeline Fabric échoue instantanément.
Cause : Mauvaise audience d'authentification dans l'action HTTP.
// Ne fonctionne PAS avec l'API Fabric
"audience": "https://analysis.windows.net/powerbi/api"// L'audience correcte pour l'API Fabric
"audience": "https://api.fabric.microsoft.com"Piège 2 : PATH_NOT_FOUND
Symptome : AnalysisException: [PATH_NOT_FOUND] Path does not exist
Cause : Le shortcut OneLake n'a pas encore synchronisé le nouveau fichier.
Solution : Rafraîchir le Lakehouse et attendre 2-5 minutes. Les shortcuts SharePoint ne sont pas instantanés — il y a un délai de synchronisation pour les nouveaux fichiers.
Piège 3 : IndexError dans le notebook
Symptome : IndexError: list index out of range
Cause : Le code original attendait un chemin complet SharePoint comme comme Shared Documents/FabricTest/file.csv, mais la Logic App envoie juste le nom du fichier.
Solution : Simplifier l'extraction du chemin pour gérer les deux cas :
parts = FullPath.strip("/").split("/")
FileName = parts[-1].split(".")[0] # Toujours le dernier élément
FileRootFolder = SHORTCUT_NAME # Utiliser le nom du shortcut, pas le parsing du cheminPiège 4 : Managed Identity non trouvé dans Fabric
Cause : Le managed identity de la Logic App n'a pas été ajouté au workspace Fabric.
Solution : Ajouter le managed identity comme Contributor dans Manage access du workspace.
10. Analyse des coûts
Cette solution est remarquablement économique :
| Composant | Coût |
|---|---|
| Logic App (Consumption) | ~0.01€/mois (quelques triggers/jour) |
| OneLake Shortcut | Gratuit (zéro duplication) |
| Fabric Notebook | Inclus dans la capacité Fabric |
| Fabric Pipeline | Inclus dans la capacité Fabric |
| Total additionnel | ~0€ au-delà de la capacité Fabric existante |
Key Takeaways
- OneLake shortcuts sont un game-changer pour connecter SharePoint a Fabric sans duplication de données
- Le design metadata-driven rend la solution évolutive — intégrez de nouveaux fichiers en ajoutant une ligne CSV, pas du code
- Logic Apps (Consumption) offrent une automatisation event-driven quasi-gratuite avec une sécurité Managed Identity
- L'audience de l'API Fabric (
https://api.fabric.microsoft.com) est différente de celle de Power BI — un piège classique - Le support Delta merge permet de gérer les rechargements complets et incrémentaux avec le même notebook
Conclusion
Construire un pipeline automatique SharePoint-vers-Fabric est plus simple qu'on ne le pense. Avec des OneLake shortcuts, un notebook PySpark, un pipeline Fabric et une Logic App, vous pouvez créer un flux d'ingestion production-ready en quelques heures — pour un coût additionnel quasi-nul.
L'insight clé est que l'integration de Fabric avec l'ecosysteme Microsoft est son superpower. Les shortcuts OneLake, l'authentification Managed Identity et l'API REST Fabric fonctionnent ensemble de manière transparente pour rendre possible des scénarios qui nécessiteraient une infrastructure complexe sur d'autres plateformes.
Si vous avez des questions ou rencontrez des problèmes, n'hésitez pas à me contacter sur LinkedIn !